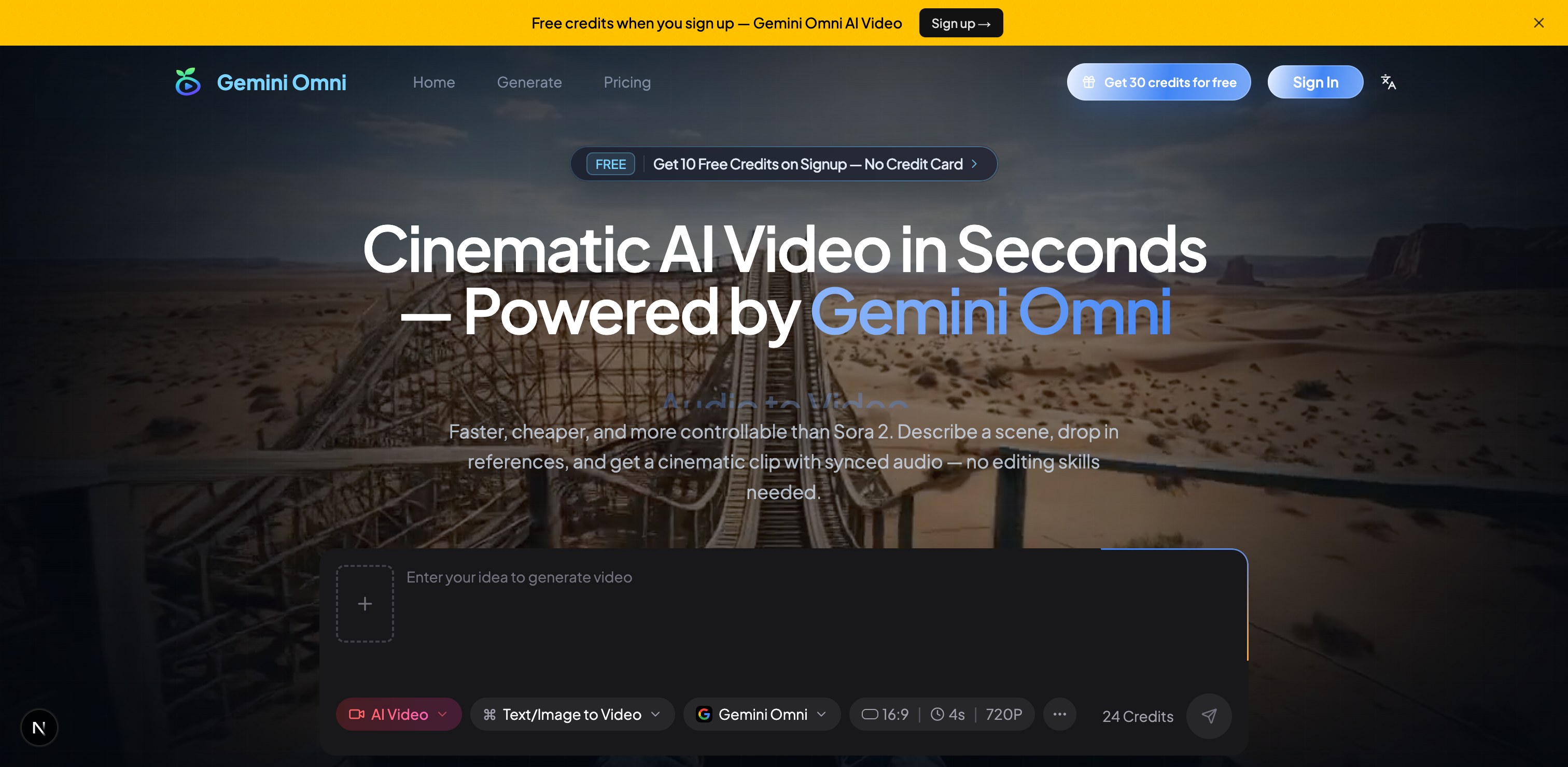
Video creation has long been a bottleneck for creators, marketers, and educators, requiring technical skill, expensive software, and hours of editing to achieve professional results. Gemini Omni AI Video Generator, powered by Google's groundbreaking omni-modal model, shatters these barriers by enabling true any-to-any video generation directly from conversational prompts, images, and audio clips, all within a single, intuitive interface.
The core value proposition of Gemini Omni lies in its native understanding of multiple data types as a unified whole. Unlike traditional video generators that treat text, visuals, and sound as separate layers, Google's omni-modal AI processes them as interconnected concepts. This allows the tool to generate videos that maintain logical scene progression, character consistency, and synchronized audio from a single, complex prompt. It’s not just stitching clips; it’s crafting a narrative with an inherent understanding of real-world physics, timing, and emotion, making it a powerful ally for rapid prototyping, content creation, and multi-shot storytelling.
Key Features
- Omni-Modal Input Processing: Describe a scene with text, provide a reference image, or upload an audio clip—or combine all three in one prompt. The AI interprets these diverse inputs as a cohesive creative brief, understanding the relationships between descriptions, visual styles, and audio cues to generate a unified video output.
- In-Chat Conversational Editing: Refine your video through a natural dialogue with the AI. Ask to change a character's outfit, extend a scene, or adjust the mood, and the model iterates directly within the chat interface. This eliminates complex timeline editing software, making video refinement as simple as having a conversation.
- Native Audio Synchronization: The AI generates or integrates audio that is natively synchronized with the visual action and pacing. Lip-sync, sound effects, and musical scoring are aligned with on-screen events by design, not added as a post-production afterthought, resulting in more immersive and professional videos.
- Persistent Character Consistency: Maintain the same characters across different scenes and shots. The AI understands and retains character attributes—appearance, style, and even subtle mannerisms—throughout a generated video sequence, enabling coherent multi-scene storytelling without manual asset management.
- Real-World Scene Logic: Generated videos adhere to plausible physical and narrative logic. Objects have appropriate weight and motion, lighting is consistent, and scenes transition in ways that make contextual sense. This moves beyond surreal AI art into the realm of usable, believable video content for practical applications.
Get Started
Getting started with Gemini Omni is straightforward and requires no specialized training. Visit the web platform, create an account, and you're immediately ready to begin prompting. The interface is designed around a central chat window where you describe your video vision. Start simple with a text-only prompt to see the AI's capabilities, then experiment by uploading a style image or an audio track to guide the generation. The conversational editing feature means there's no penalty for an imperfect first prompt; you can refine and iterate in real-time. The platform offers a generous free tier, allowing you to explore its core multimodal generation and editing features without an initial investment, making it an accessible tool for professionals and hobbyists alike to integrate into their content creation workflows.